Tying some ancient rituals and historical events together, this after school video highlights one of the intersting ideas that resonated in my thirties. To truly live, or love, one must let go, one must surrender, and experience the dissolution of ego. Its interesting how the word ego itself seem to indicate that it must ‘go’, and the letter ‘e’ perhaps indicating the external. In a way, let go of the external world, and look inward - to experience the self, love and life.
Asynchronous Event driven applications are becoming ever more common, and testing the
correctness of these applications can be tricky. However, there are some techniques and
tools available to aid testing asynchronous code - one such tool is a CountDownLatch.
Executing Concurrent Tasks
Suppose we have an application that runs simple tasks.
These tasks can take varying amount of time to finish.
Upon the completion of a task, a task can be marked as executed.
If we have to write a very basic test case for the task runner, it may look like:
@TestpublicvoidtestExecution()throwsInterruptedException{// Generate Sample TasksList<Task>tasks=newArrayList<>();for(inti=0;i<10;i++){tasks.add(newTask("Task "+i));}taskRunner.executeTasks(tasks);// Give the tasks sufficient time to finishThread.sleep(2000);for(Tasktask:tasks){assertTrue(task.hasExecuted());}}
In the above test we had to a Thread.sleep() of 2 seconds because the tasks may not have finished before we reach assert statements.
However, the tasks may take more or less than 2 seconds to finish.
There are at least two problems with this approach:
The test is unreliable, as running the tests on a faster or slower machine or build agent influences the result of the test.
These kind of tests also make the build slower when unit tests are run as part of the build. This goes against the principles of Continuous Integration
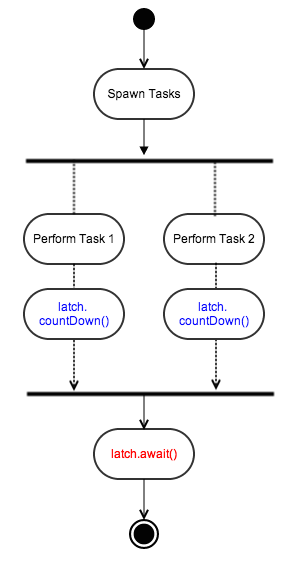
We can circumvent these concerns with a CountDownLatch.
What is a CountDownLatch?
A CountDownLatch is a construct that allows one or more threads to wait until a set of operations being performed in other thread completes.
The latch is initialised with a Count, a positive integer e.g. 2
The thread that calls latch.await() will block until the Count reaches to Zero
All other threads are required to decrement the Count by calling latch.countDown()
Once the Count reaches Zero, the awaiting thread resumes execution
Once a latch reaches Zero, it can no longer be used, a brand new latch needs to be created.
However, a CyclicBarrier may be more suited for such requirements.
The following is a simple usecase of how to use a CountDownLatch:
CountDownLatchlatch=newCountDownLatch(3);ExecutorServiceexecutor=Executors.newCachedThreadPool();// submit three tasksfor(inti=0;i<3;i++){executor.submit(newRunnable(){@Overridepublicvoidrun(){// do long running task hereSystem.out.println("Performing long task...");// when task finished, countDownlatch.countDown();}});}// wait until task is finishedlatch.await();System.out.println("All tasks are done!! ");executor.shutdown();
Better Tests using Latch
TestRunner test we discussed previously using Thread.sleep(...) can be written using a CountDownLatch.
Note how the test calls latch.await() to wait for all tasks to finish before it can verify the assertions.
@TestpublicvoidtestExecutionLatch()throwsInterruptedException{CountDownLatchlatch=newCountDownLatch(10);List<Task>tasks=newArrayList<>();for(inti=0;i<10;i++){// Create latched tasks that countdowns the latch when it finishestasks.add(newTask("Task "+i){@Overridepublicvoidrun(){super.run();latch.countDown();}});}taskRunner.executeTasks(tasks);// wait for all tasks to finishlatch.await();for(Tasktask:tasks){assertTrue(task.hasExecuted());}}
If a Task doesn’t finish due to a bug in our TestRunner implementation, then test may forever block.
Thus, its a good idea to impose a timeout on our tests either by introducing timeout parameter in the
@Test annotation e.g. @Test(timeout=2000) or simply specifying a timeout in the await
latch.await(2, TimeUnit.SECONDS);.
Since the addition of Traits in Groovy 2.3, it becomes easier to implement the vision of DCI Architecture.
The trait construct replaces the previously available @Mixin transformation, making traits a first class
construct in the language itself. In this article we will explore how a simple DCI application can be developed
using Groovy Traits.
What are Traits?
Traits are a structural construct of the language that allow composition of behaviours.
Similar to the interface construct in Java, traits are used to define object types by specifying supported methods.
But unlike interfaces, traits can be partially implemented - allowing traits to provide default implementations for types.
Traits can be used to implement multiple inheritance in a controlled way, without running into the diamond problem.
Groovy resolves multiple inheritance conflicts by letting the last declared trait’s method to win.
Traits provide a powerful design alternative to Inheritance for reusing behaviours.
As an example, the concept of an Account can be modelled using traits.
This allows us to create a reusable unit of behaviour that can be applied to any objects.
Following is an example of how such a trait is declared:
The trait of account can be used to represent a Savings Account Object, it can also be applied to other objects e.g. a Student Object to represent the concept of a Student Account. For a simple example, we will just represent two account types using the Account trait:
DCI (Data, Context, Interaction) is a vision to capture the end user cognitive model of roles and interactions between them.
The paradigm separates the domain model (data) from use cases (context) and Roles that objects play (interaction).
This allows us to cleanly separate code for rapidly changing system behavior (what the system does)
from code for slowly changing domain knowledge (what the system is).
DCI promotes the decoupling of a Role that an object plays from the object itself.
The same object can play different roles depending on the context.
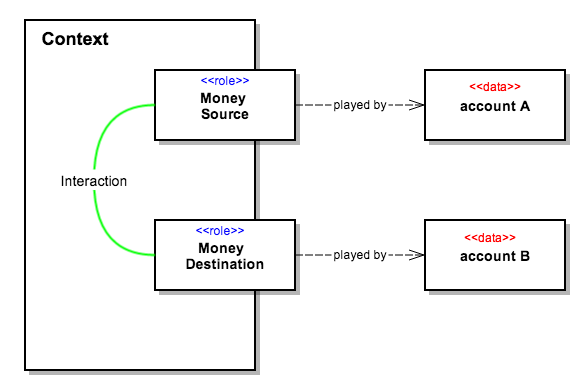
In our example, the same Account object can play the role of money source or a money destination in different transactions.
These roles can be represented by the following Traits:
traitTransferMoneySourceimplementsMoneySource{voidwithdraw(doubleamount,MoneyDestinationdest){if(getBalance()>amount){this.decreaseBalance(amount)dest.deposit(amount)this.updateLog"Withdrawal of ${amount} performed"}else{thrownewIllegalArgumentException("Insufficient Balance in Source")}}}traitTransferMoneyDestinationimplementsMoneyDestination{publicvoiddeposit(doubleamount){increaseBalance(amount)}}
Binding The Roles to Objects in a Use Case
The Context in DCI enacts the use-case by assigning roles to objects, and then the objects interact as their roles.
Below, the first account plays the role of a Money Source, and the second account plays the role of a Money Destination.
The Groovy as keyword binds the role trait to the object that plays the role.
The objects in a use-case collaborate using only role methods.
classWithdrawalContext{Accountsource,destdoubleamountdefexecute(){// Apply the role of a MoneySource to a source AccountMoneySourcemoneySource=sourceasTransferMoneySource// Apply the role of a MoneyDestination to a destination AccountMoneyDestinationmoneyDestination=destasTransferMoneyDestination// Perform the usecasemoneySource.withdraw(amount,moneyDestination)}}
DCI allows the source code to reflect the run-time structure, as the network of interactions between Roles in the code is the same as the corresponding network of objects at run time.
The following picture illustrates this network of interactions:
A sample application executing the use-case may look like:
When representing time in software, we need to be aware of the nature of time.
Improper handling of time can easily create tricky issues that are hard to identify.
It took the genius of Albert Einstein to fully understand the true nature of time.
Time can’t exist without a location in space, as space and time are inter-connected.
Simply put, if it is 9 AM in Sydney, it is not necessarily 9 AM everywhere in the universe
(unless of course you have a broken watch). Without going into too much details of the physical properties of time,
the important consequence of this concept is:
To accurately represent or measure time in computer software, one must take into account the location where the time was measured.
There is no silver bullet or a technology framework that can solve all time related problems if we don’t understand the above nature of time.
Time is Relative and Contextual
When modelling time, we usually deal with two types of time data, Civil Time and Physical Time.
Civil Time
Civil time is represented as a point on a Calendar or a local clock as agreed by civilian authorities.
This is the type of time data we use in our day to day conversations. When capturing Civil Time, we need to be aware of the context in which it is specified.
As an example, when we say “Lets catch 9’o clock bus” - a lot of information is implied by the context of the speaker.
Such implied or implicit context is not always available in software design, and needs to be explicitly specified
if the software will be used in more than one time zones.
Therefore, we need to be mindful of the context and timezone when modelling time.
In addition, we also need to be aware of local transformations such as Day Light Saving Time (DST).
Physical Time
Physical Time is represented as a point in the continuous universal timeline.
This kind of time data can be adequately represented in Universal Time (UTC),
which is calculated by reference to atomic clocks. Physical time is useful in storing calculations
and measurements, as it is unambiguous and context-free.
Best Practices
Time is a complex topic, however we can still follow some best practices to avoid some pitfalls that may occur in
distributed client-server applications.
Persist Globally, Display Locally
When you store time, store it in UTC and use server time. UTC time is DST agnostic,
thus it is a good approach of storing time without confusion.
Delayed/Late Conversion
Only apply timezone/DST in the Last possible moment when you display the time to client.
Only apply timezone formats at the very end, when the time is being displayed at the client terminal/browser.
When converting to timezone, remember that timezones may change, and an entire state or country may not be in the same timezone.
Capture Context
When capturing Time as input, take into consideration how the client is specifying the time,
and for what purpose. Understand the context in which a time related information is specified.
Here are a few examples of different contexts where the meaning of time can vary:
Example Type
Example Usage
Contextual Meaning
Event Time
The concert is going to start at 10pm
Event time is always relative to the location of where the event takes place
Contract Time
The car insurance is valid till 31st January next year
Depending on the insurance company’s policies, the policy may expire at 5pm 31st January depending on where the policy is purchased from. Exact meaning needs to be clarified.
Recurring Time
The TV show airs every day at 9am
Everyday at 9am local time, regardless of DST
Floating Durations
Tech support available during Business Hours, Express Trains available during Peak Hours on Weekdays
Always based on local time and day of week, subjected to holidays etc.
Time interval or relative time
Contract is due for renewal every year, or we charge you phone fee on a monthly basis
Storing agreed interval from a reference point.
Use the Universally Accepted ISO format for Web Services
When designing web based services that expose time
(e.g. created date, modified data) it is best to keep it in a human readable ie. string form rather than a long number.
It allows interoperability between different types of clients, and also allows humans to understand and debug the service.
Standardised formats as ISO 8601 should be considered.
Prefer ISO date format in representing date/time for web services over Numeric time (e.g. Long 1341542232312)
which has limited readability, usability or portability.
ISO date format is the best choice for a date representation that is accurately/universally (e.g. W3C) understandable.
Majority of websites today use JavaScript to do more than just hide or show a button.
As code complexity grows, it becomes harder to understand and maintain JavaScript code.
In this example, two approaches of designing an application will be contrasted to highlight the benefits of a modular design.
Although the example is a simple game application, it still demonstrates how breaking an application into loosely coupled modules makes it easy to understand,
extend and maintain.
Designing a Path Finding Game
The purpose of the application is to demonstrate different path finding algorithms for a game that involves a cat looking
for a cake on an interactive board. The user can draw obstacles on the board by clicking on the tiles,
and move the cat or cake to set its positions. The game can then determine a path that allows the cat
to find the cake when a “Find Path” button is pressed. This is how the end result may look like:
Classic Approach
Using a classic JavaScript design approach, we can do the following:
Use divs to represent the board and the actors, which are then manipulated using jQuery
Assign a CSS class to a div to represent various elements of the game:
an empty square - .square
a square with an obstacle - .obstacle
a square with the actor cat - .actor
a square with the goal cake - .goal
Write a function that will query the divs using jQuery class selectors to find the positions of the cat and cake to determine the solution
In such approach, the view state and application state may get mixed together - as there are no clear separation between model and view. The setup code for the board might look like:
// generate the board layout consisting of squaresfor(varrow=0;row<rows;row++){for(varcol=0;col<cols;col++){$('div.board').append('<div class="square" row="'+row+'" col="'+col+'"></div>')}}// toggle between obstacle and open when a square is clicked$('div.board').find(".square").click(function(){$(this).toggleClass('obstacle')})
When the game’s actor cat is dropped on a square to specify a starting position, the class attributes of the divs are updated:
// when the actor is dropped on a square$('.square').droppable(function(){$('.actor').removeClass('actor')$(this).addClass('actor')})
In this design, the code to move an actor to the square at position [10,15] may look like:
Next step would be to implement the path finding algorithm. Without going any further, we can already start to notice that most of our code is entangled with jQuery.
Such code may look simplistic at first, but it is hard to maintain as application logic is diffused with DOM manipulations.
With time, it will become harder to follow how everything fits together - as everything is glued together with CSS selectors and callbacks.
This monolithic approach makes it hard to write reusable code as most functions are littered with view specific jQuery code.
If we have to change how the view is generated, we would have to change many places of the code - we may even miss a few places.
Alternative Modular Approach
We can start by identifying clusters of functions or objects that relate closely to a single domain concept. Also, we would like to separate the concerns of displaying the board/actors from the Game so that there is a clean separation between view and business logic. Thus, we come up with:
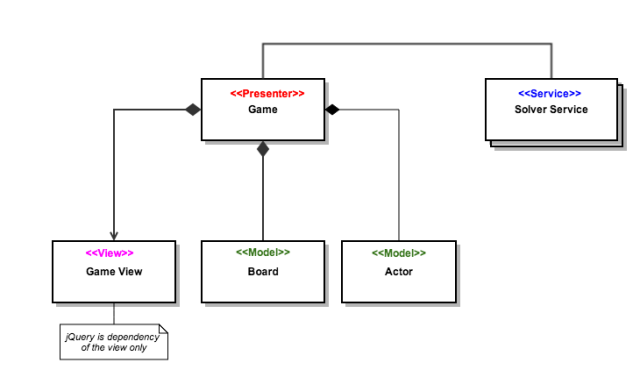
Board - Represents a Grid containing open tiles and obstacles
Actor - Represents the actor of the game - the Cat
Game - Co-ordinates the elements and rules of the game
Game-View - Visualising the state of the game.
Solver Service - A service or strategy to find a path from the Actor to the goal on the board. This could also be a remote service using AJAX.
We can map these cluster of functions or objects into modules. This will allow us to clearly mark the boundaries and dependencies between different parts of our application.
Identifying the specific roles of objects allow us to apply a design pattern like MVC or MVP to glue the loosely coupled parts together.
In this example, the Game object performs the role of the Presenter and the Board/Actor objects together comprise the Model. All View concerns are encapsulated in the Game-View module.
The following illustration shows the relationship between the application objects:
With such separation of concerns and single responsibility, the code to move the actor to a square will look like:
Any interaction that happens in the view is handled by the Game Presenter:
// Inside Game Presenter// View object - Pass Presenter callbacks for event handlingvargameView=newGameView(options,{onObstacleChange:function(isObstacle,row,col){board.setObstacle(isObstacle,row,col)gameView.reset()},onNewStartPosition:function(row,col){actorPos=newPosition(row,col)gameView.reset()},onNewGoalPosition:function(row,col){goalPos=newPosition(row,col)gameView.reset()}})
The modular design allows us to load different Service/Strategies for solving the game - which may be loaded lazily as required:
// Solver Service returns a list of moves that leads the cat to the cakevarsolution=SolverService.solve(board,actorPos,goalPos)solution.forEach(function(position){game.moveActor(position)})
In summary, the modular design allows us to create reusable components that can be easily tested and maintained.
Application logic is cleanly isolated from view/DOM manipulation logic as we have moved all jQuery code into our view module.
This makes the code much easier to comprehend. Since the dependencies between modules can be explicitly defined,
the runtime can load modules in parallel to reduce application load time.
If you would like to play with the sample application, please find it here:
git clone https://github.com/openraz/javascript.git


 When representing time in software, we need to be aware of the nature of time.
Improper handling of time can easily create tricky issues that are hard to identify.
When representing time in software, we need to be aware of the nature of time.
Improper handling of time can easily create tricky issues that are hard to identify.